Linear algebra is the branch of mathematics concerning linear equations such as \(a_1 x_1 + \cdots a_n x_n = b,\) and linear maps such as \((x_{1},\ldots ,x_{n})\mapsto a_{1}x_{1}+\cdots +a_{n}x_{n},\) and their representations in vector spaces and through matrices.
Link between Data science and Linear Algebra
Data are organized in rectangular array, understood as matrices, and the mathematical concept associated with matrices are used to manipulate data.
Palmer penguins illustration
## install.packages('palmerpenguins")library("palmerpenguins")penguins_nona <-na.omit(penguins) ## remove_na for nowpenguins_nona |>print(n=3)
# A tibble: 333 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
# ℹ 330 more rows
# ℹ 2 more variables: sex <fct>, year <int>
One row describes one specific penguin,
One column corresponds to one specific attribute of the penguin.
Focusing on quantitative variables, we get rectangular array with n=333 rows, and d=5 columns.
Each penguin might be seen as a vector in \(\mathbb{R}^d\) and each variable might be seen as a vector in \(\mathbb{R}^n\). The whole data set is a matrix of dimension \((n,d)\).
Linear Algebra : What and why
Regression Analysis
to predict one variable, the response variable named \(Y\), given the others, the regressors
or equivalently to identify a linear combination of the regressors which provide a good approximation of the responsbe variable,
or equivalently to specify parameters\(\theta,\) so that the prediction\(\hat{Y} = X \theta,\) linear combination of the regressors which is as close as possible from \(Y\).
We are dealing with linear equations, enter the world of Linear Algebra.
Principal Component Analysis
to explore relationship between variables,
or equivalently to quantify proximity between vectors,
but also to define a small set of new variables (vectors) which represent most of the initial variables,
We are dealing with vectors, vector basis, enter the world of Linear Algebra.
Linear Algebra Basic objects
Vectors
\(x\in \R^n\) is a vector of \(n\) components.
By convention, \(x\) is a column vector\[x=\begin{pmatrix} x_1 \cr \vdots\cr x_n \end{pmatrix}.\]
When a row vector is needed we use operator \(\ ^\intercal,\)
The term on row \(i\) and column \(j\) is refered to as \(a_{ij}\),
The column \(j\) is refer to as \(A_{.,j}\), \(A_{.,j} = \begin{pmatrix} a_{1j} \cr \vdots\cr a_{nj} \end{pmatrix}.\)
To respect the column vector convention, the row \(i\) is refer to as \(A_{i,.}^\intercal\), \(A_{i,.}^\intercal = \begin{pmatrix} a_{i1}, & \cdots & , a_{id} \end{pmatrix}\)
Let \(A\in \R^{n \times p}\) and \(B\in\R^{p \times d}\), then the product \(AB\) is well defined, it is a matrix \(C\) in \(\R^{n\times ,d}\), so that
As a vector \(x\) in \(\R^n\) is also a matrix in \(\R^{n\times 1}\), the product \(A x\) exisst is the number of columns in \(A\) equals the number of row for \(x\).
The transpose, denoted by \(\ ^\intercal\), of a matrix results from switching the rows and columns. Let \(A \in \R^{n\times d}\), \[A^{\intercal} \in \R^{d\times n},\ and (A^{\intercal})_{ij}= A_{ji}.\]
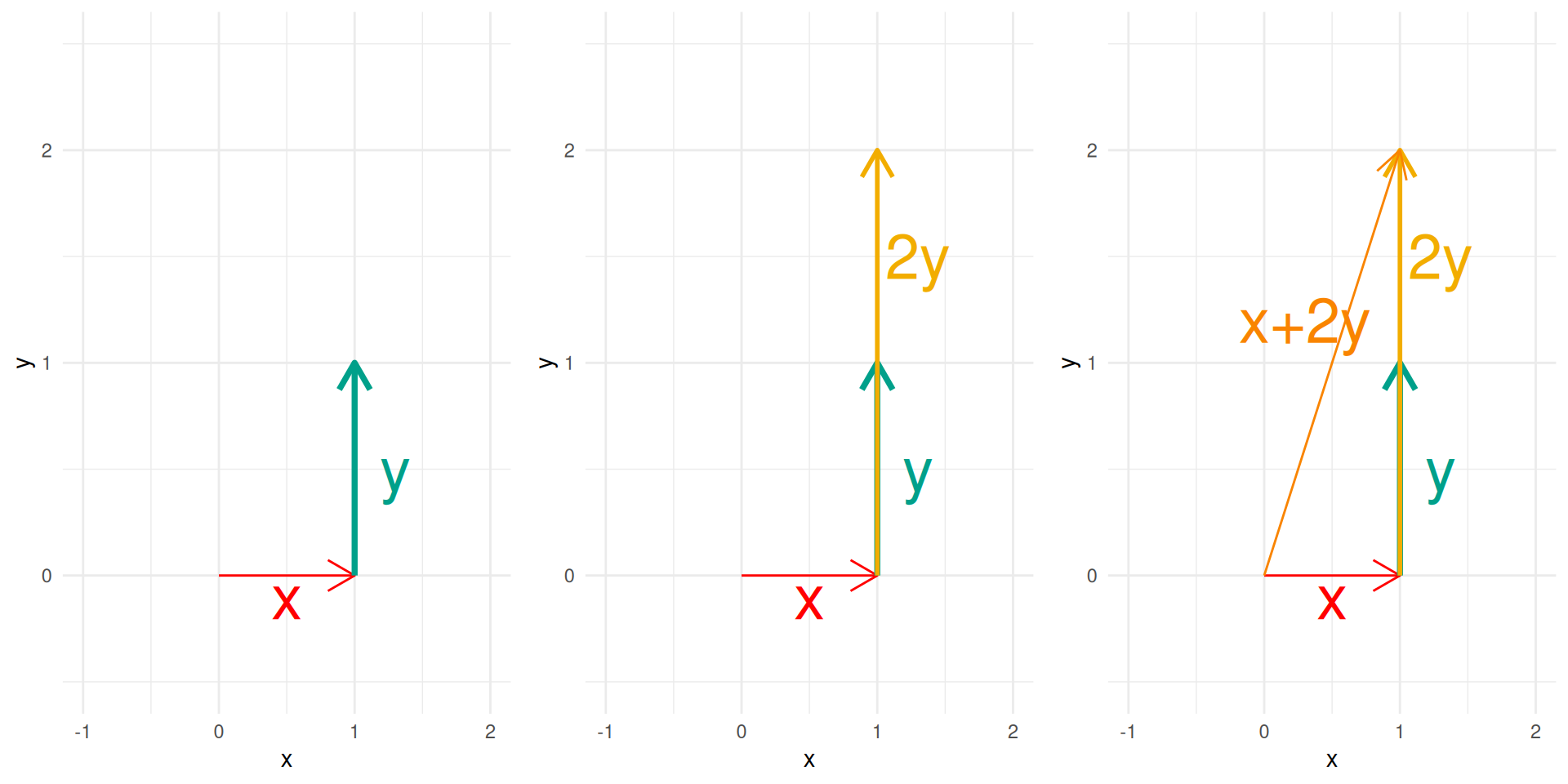
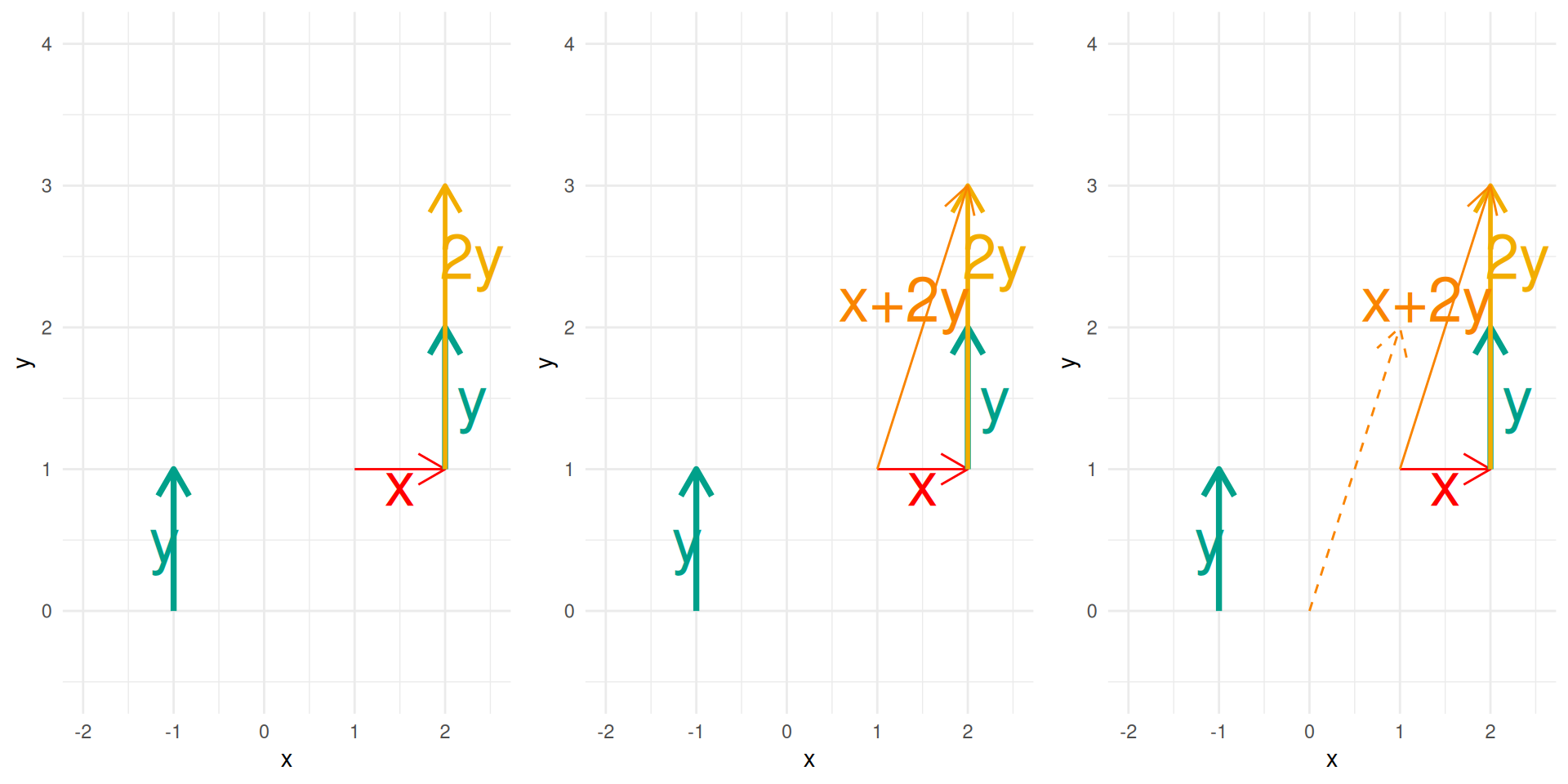
Let \(x,y\) be in \((\R^n)^2,\) the dot product, also known as inner product or scalar product is defined as \[x\cdot y = y\cdot x = \sum_{i=1}^n x_i y_i = x^\intercal y= y^\intercal x.\] The norm of a vector \(x\), symbolized with \(\norm{x},\) is defined by \[\norm{x}^2 =\sum_{i=1}^n x_i^2 = x^\intercal x.\]
A sequence of vectors \(x_1, \cdots, x_k\) from \(\R^n\) is said to be linearly independent, if the only solution to \(\sum_{i=1}^k a_i x_i =\mathbb{0}\) is \(a =\mathbb {0}\).
The span of a set of vectors is the set of all possible linear combinations of these vectors.
In other words, if you take some vectors \(v_1, v_2, \dots, v_k\), their span is the collection of vectors you can build by multiplying each \(v_i\) by a scalar and then adding the results together.
A real vector space \((V, +, . ,\R)\) is a set \(V\) equipped with two operations satisfybing the following properties for all \((x,y,z)\in V^3\) and all \((\lambda,\mu)\in\R^2:\)
(close for addition)\(x + y \in V,\)
(close for scalar multiplication)\(\lambda x \in V,\)
(commutativity)\(x + y = y + x,\)
(associativity of +)\((x + y) + z = x + (y + z),\)
(Null element for +)\(x + \mathbb{0} = x,\)
(Existence of additive inverse +) There exists \(-x \in V\), such that $ + (-x) = ,$
(Distributivity of scalar sums)\((\lambda + \mu ) x = \lambda x + \mu x,\)
(Distributivity of vector sums)\(\lambda (x + y ) = \lambda x + \lambda y,\)
(Scalar multiplication identity)\(1 x = x.\)
It is enough for the course to think to the set of vectors in \(\R^d\).
Basis of a Vector Space
A set B of elements of a vector space V is called a basis if every element of V can be written in a unique way as a finite linear combination of elements of B.
A subset \(B \subset V\) is a basis if it satisfies the two following conditions:
Linear independence. For every finite subset \(\{ \mathbf{v}_1, \dotsc, \mathbf{v}_m \}\) of \(B\),
if \[
c_{1}\mathbf{v}_{1} + \cdots + c_{m}\mathbf{v}_{m} = \mathbf{0} \Longleftrightarrow
c_{1} = \cdots = c_{m} = 0.
\]
Spanning property. For every \(\mathbf{v} \in V\), there exits \(a_{1}, \dotsc, a_{n} \in \R\) such that \[
\mathbf{v} = a_{1}\mathbf{v}_{1} + \cdots + a_{n}\mathbf{v}_{n}.
\]
The coefficients of this linear combination are referred to as components or coordinates of the vector with respect to B. The elements of a basis are called basis vectors.
If \(\norm{v_i} =1\) for all \(i\), the basis is orthonormal.
\(\left (\begin{pmatrix} 1 \\ 0 \end{pmatrix}, \begin{pmatrix} 0 \\ 1 \end{pmatrix}\right )\) is a basis of \(\R^2\)
Check whether or not these sets of vectors form orthobormal bases
in \(\R^3\)\[{v}_1=\frac{1}{\sqrt{3}}\begin{pmatrix}1\\1\\1\end{pmatrix},\qquad v_2=\frac{1}{\sqrt{2}}\begin{pmatrix}1\\-1\\0\end{pmatrix},\qquad {v}_3=\frac{1}{\sqrt{6}}\begin{pmatrix}1\\1\\-2\end{pmatrix}.\]
Link with Linear applications
Linear mapping
Let \(f\) be a function from \(\R^d\) to \(\R^n\), \(f\) is linear if and only if
For all \((\lambda,\mu) \in \R^2\) and for all \((x,y) (\R^d)^2,\)\[f(\lambda x + \mu y ) = \lambda f(x) + \mu f( y )\]
Example
\[\begin{align}
f : \R^2 & \to \R\cr
x & \mapsto x_1-x_2
\end{align}\]
\[f(x) = A x, \quad A = \begin{pmatrix}
1 & -1
\end{pmatrix}\]
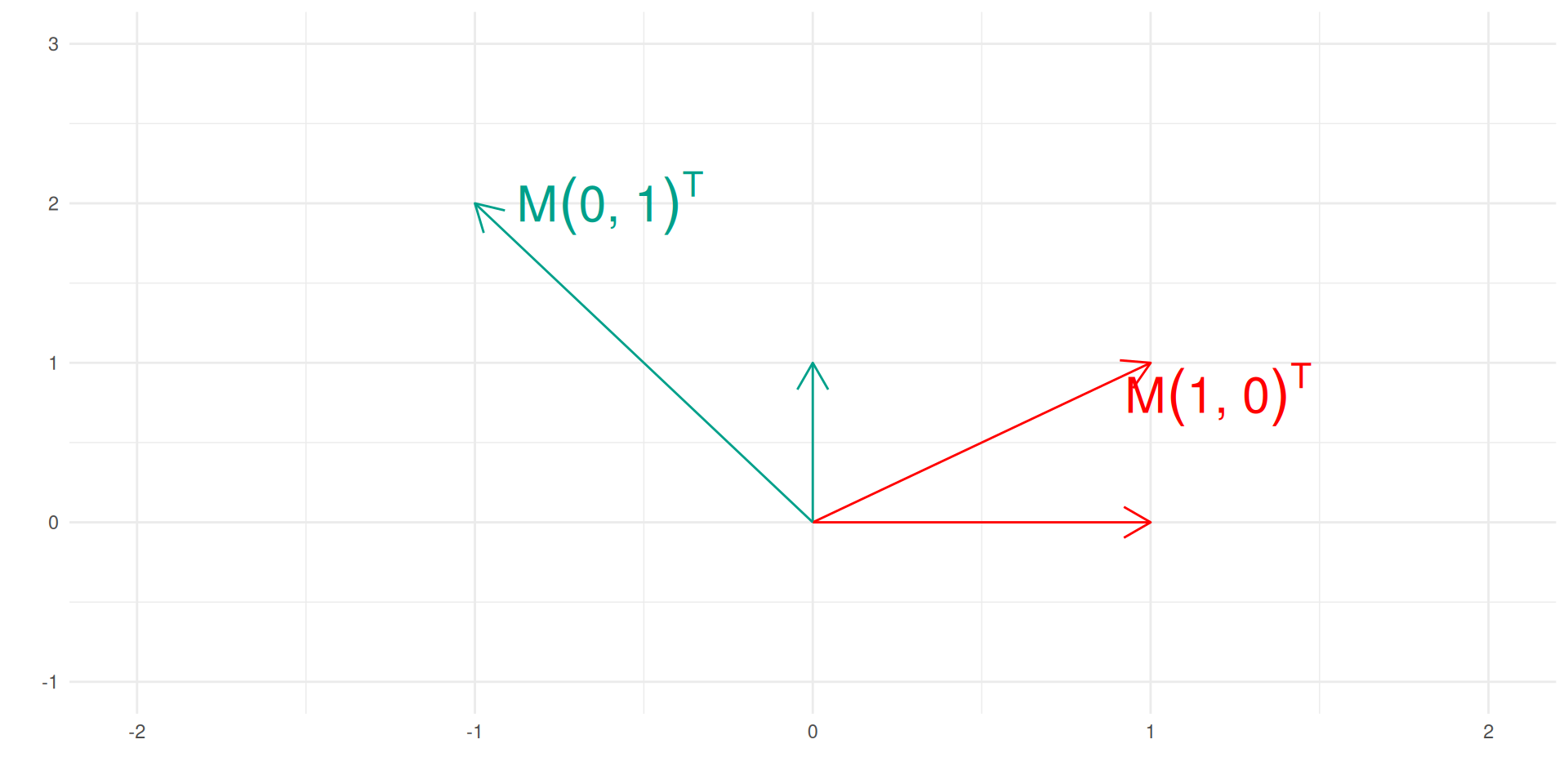
Matrix as a linear map on vector space
A real matrix \(A\in\R^{n\times d}\) is a linear function operating from one real vector space of dimension \(d\) to real vector space of dimension \(n\).
\[\begin{align}
A: &\R^d \to \R^n\\
& x \mapsto y = Ax
\end{align}\]
Square Norm \(f\) of \(x\) equals \(x_1^2 + x_2^2,\) As \(f(\lambda_1 x ) = \lambda_1^2 f( x)\), the square norm is not a linear function and could not be expressed as a matrix.
Matrix rank
The sequence of columns of a matrix \(M\in \R^{n\times d}\) forms a sequence of \(d\) vectors \((c_1, \cdots,c_d)\) in \(\R^n\), while the rows of a matrix forms a sequence of \(n\) vectors \((r_1, \cdots,r_n)\) in \(\R^d\).
The rank of a matrix is the length of the largest sequence of linearly independent columns or equivalently the length of the largest sequence of linearly independent rows.
\(Im(A) = \left \lbrace y \in \R^n; \exists c\in R^d, y = \sum_{l=1}^d c_l A_{., l} \right \rbrace\)
Remarks
If \(A_{.,1}\) and \(A_{,2}\) are linearly dependant, \(A_{,1} = \lambda A_{,2}\) and \(Ac = ( c_1 \lambda + c_2) A_{.,2} + \cdots + c_d A_{.,d}\). The rank is the minimal number of vector to generate \(Im(A)\), that is the dimension of \(Im(A)\).
Remarkable matrices
Identity matrix
The square matrix \(I\) such \(I_{ij} =\delta_{ij}\) is named the Identity matrix and acts as the neutral element for matrix multiplication
Let \(I_n\) be the identity matrix in $^{nn}, for any \(A \in \R^{m\times n}\), \(A I_n = A\) and \(I_m A = A\).
Diagonal matrix
A Diagonal matrix is a matrix in which elements outside the main diagonal are all zeros. The term is mostly used for square matrix but the terminology might also be used otherwise.
An orthonormal matrix \(A\) admits an inverse and this inverse is simply \(A^\intercal\).
How are matrices used in Data Science
Solving Linear systems
Matrices provide a compact way to represent and solve systems of linear equations, which appear in regression models, optimization problems, and numerical simulations.
Identifying Invariant Directions
Matrices help reveal invariant directions in data transformations. This is the foundation of techniques like Principal Component Analysis (PCA), which reduces dimensionality while preserving essential structure.
Linear systems
Numerically, linear regression sums solving a linear system \[ X \theta = b.\] where \(X\in \R^{n\times p}\), \(\theta\in\R^p\) and \(b\in \R^n\). Assume \(n>=p\).
There exists a solution given by \[\hat{\theta} = X_L^{-1} b, \]\(X_L^{-1}\) to be determined.
The model is underdetermined, and admits several solutions. This happens when
the regressors in \(X\) are dependent, and in this case this is solved by adding additionnal linear constraint that \(\theta\) should respect.
too few observations \(n<p\), and this solved by adding penalities terms (LASSO and RIDGE regression for example)
Gram–Schmidt Orthonormalization
The Gram–Schmidt process transforms a linearly independent set of vectors \[\mathbf{v}_1, \mathbf{v}_2, \dots, \mathbf{v}_n\] in an inner product space into an orthonormal basis\[\mathbf{u}_1, \mathbf{u}_2, \dots, \mathbf{u}_n.\]
The resulting set \(\{\mathbf{u}_1,\mathbf{u}_2,\mathbf{u}_3\}\) is an orthonormal basis of (^3).
Eigen values, Eigen vectors
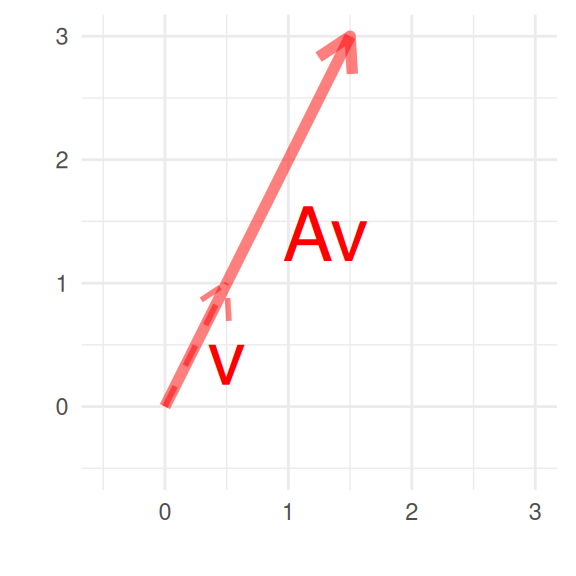
Consider a square matrix, \(A \in \R^{d\times d}\), and a nonzero vector, \(v \in \R^d\), \(v\) is an eigen vector for the eigen value\(\lambda\) if \[Av = \lambda v.\] If \(v\) is an eigen vector for \(A\), applying \(A\) to \(v\) just consists in multiplying by the corresponding eigen value.
Identify the eigen values and eigen vectors for \(A_1 = \begin{pmatrix}1 & 0 \cr 0 & 2\end{pmatrix}\), \(A_2 = \begin{pmatrix}1 & 3 \cr 0 & 2\end{pmatrix},\)\(A_3 = \begin{pmatrix} 2 & 2 \cr -2 & 2 \end{pmatrix}.\)
Singular Value Decomposition (SVD)
Let’s \(A\) a \(n\times d\) matrix of rank \(r\), there exists a \(n\times n\) orthogonal matrix \(P\), a \(d\times d\) orthogonal matrix \(Q\), and \(D_1\) a diagonal \(r\times r\) matrix whose diagonal terms are in decreasing order such that: \[ A = P
\begin{pmatrix} D_1 & 0 \cr
0 & 0 \cr
\end{pmatrix} Q^\intercal\]
For a nice and visual course on SVD see the Steve Brunton Youbube Channel on this subject!