Importation de données dans RStudio
But
Ce document est un aide-mémoire pour réussir l’importation des données dans R. En suivant les différentes étapes, tout devrait bien se passer.
L’objectif sera donc ici d’importer le jeu de données stockés dans le fichier Excel samares disponible sur la page des données
Etape 1. Créer un projet
Rstudio proposer d’organiser son travail en projet. Le projet permet de faciliter l’accès aux différents fichiers d’un même projet. Pour créer un projet il suffit d’aller en haut à droite, dans Project comme dans la capture d’écran ci-dessous.
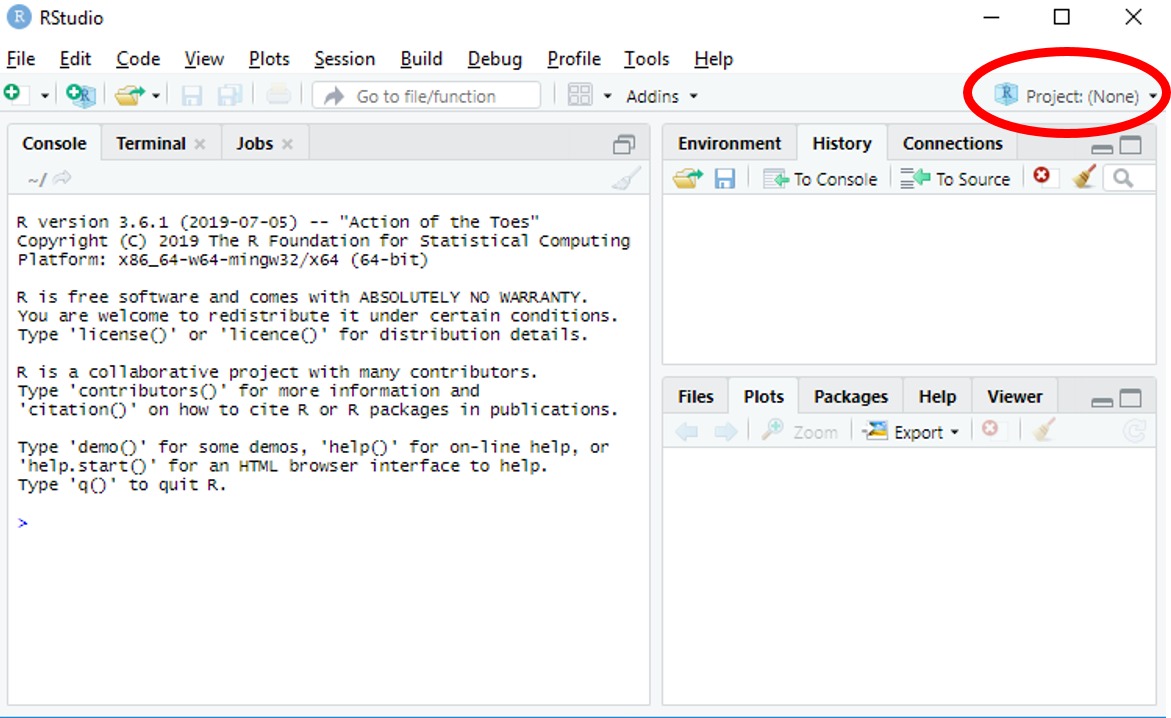
On choisit de créer le projet depuis un nouveau répertoire
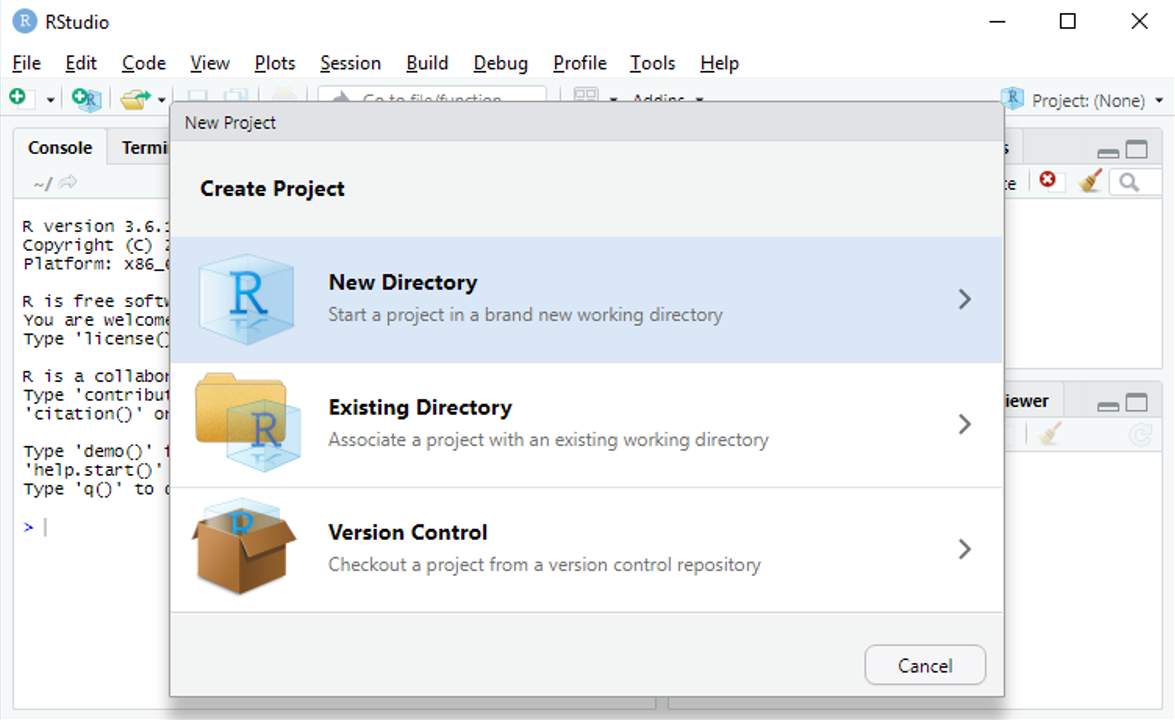
et de faire un projet standard
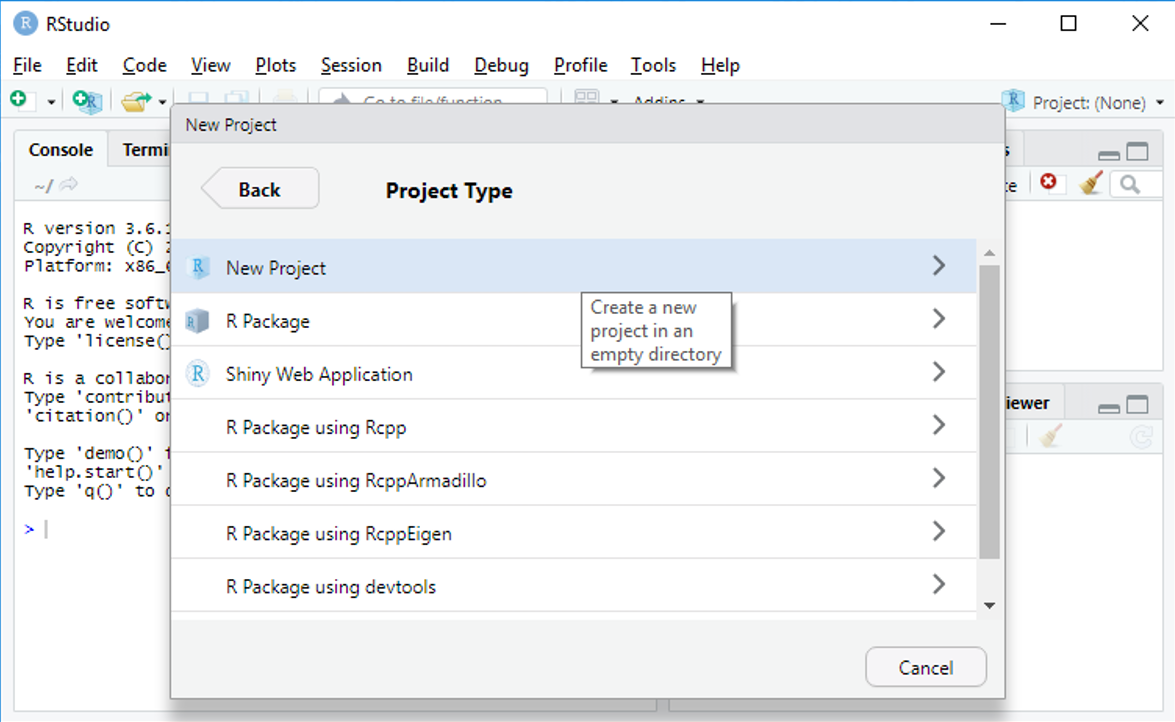
qui s’appelera Td_Stat_1 et sera placé dans le répertoire désigné
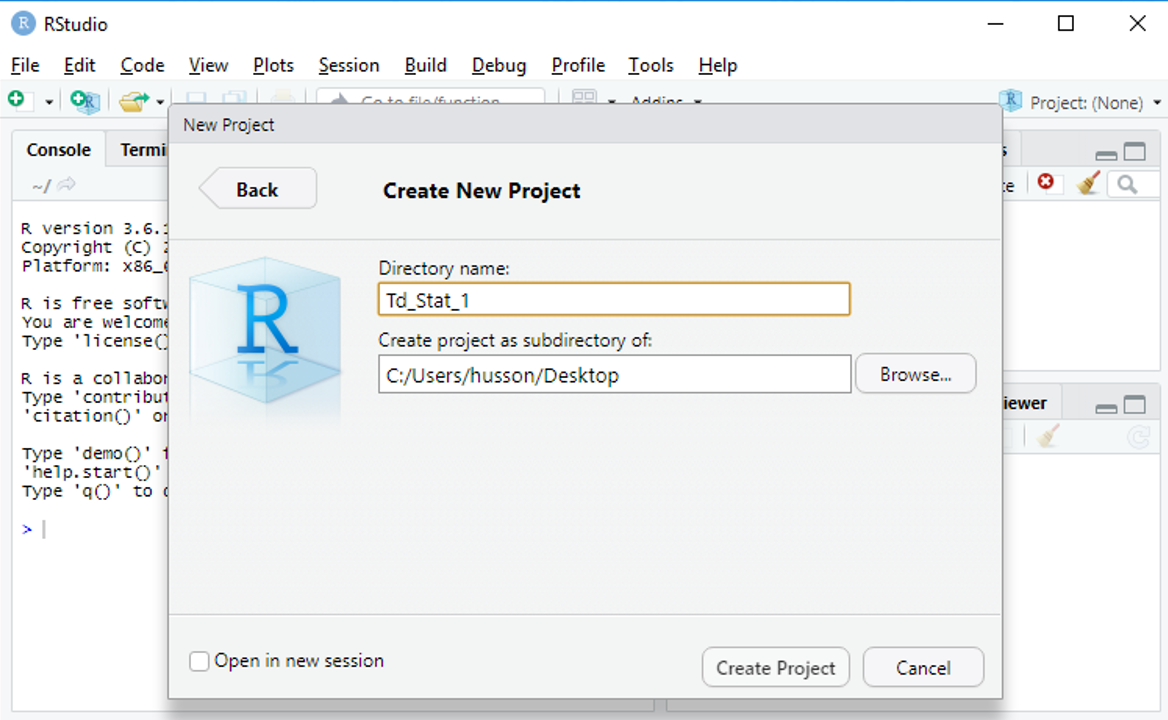
Etape 2. Créer un script
Les instructions dans R sont écrites dans un fichier de script. Ce fichier permet de garder trace de toute l’analyse que vous mettrez en oeuvre.
On ouvre donc un nouveau script File -> New File ->
Rscript. En haut du script, on indique la date, et le but de
l’analyse en faisant précéder les débuts de lignes par des
#.
Les lignes qui commencent par # ne sont pas interprétées
par R, elles permettent de faire des commentaires.
Etape 3. Télécharger le fichier
Le fichier est disponible sur la page des jeux de données
On peut le sauvegarder sur le disque en faisant un clic droit et en choisissant ‘Save as’ ( ou ‘Sauvegarder la cible du lien sous’ ou tout autre formulation similaire). On choisit de le sauver dans le répertoire du projet qu’on vient de créer précédemment.
Etape 4. D’un format propriétaire à un format texte
Le format Excel est complexe et varie d’une plateforme à l’autre,
d’une langue à l’autre …. Pour éviter les surprises, il est préférable
d’exporter son fichier au format csv. Dans Excel, il suffit
d’aller dans le menu File puis Save as et de choisir l’extension csv
dans le menu déroulant des types de fichier puis de le sauver dans le
répertoire du projet sous le nom samares_small.csv. On a
donc un fichier samares_small.csv dans le répertoire du
projet.
Etape 5. Comprendre le format du fichier de données
En ouvrant le fichier `samares_small.csv’ avec un éditeur de texte (Notepad++ sous Windows, gedit sous Linux, TextWrangler sous Mac OS par exemple), on peut voir le fichier brut et le début doit ressembler à :
Etude d’une potentielle sélection génétique sur les capacités de dispersion du frêne,,,,,,,,,,
Données partielles,,,,,,,,,,
Source : perdue ,,,,,,,,,,
Site,NomSite,Distance,Arbre,Poids,Surface,Largeur,Longueur,CircArbre,dispersion,log_disp
1,Grenou_1,0,1,16.8,0.83907,0.45758,2.46212,57,0.049944642857143,-2.99684002974653
1,Grenou_1,0,1,25.4,0.80864,0.43251,2.47986,57,0.031836220472441,-3.4471506288068
1,Grenou_1,0,1,21.7,0.77436,0.44081,2.35872,57,0.035684792626728,-3.3330306577928
1,Grenou_1,0,1,14.9,0.86005,0.45292,2.63522,57,0.057721476510067,-2.85212596484115
1,Grenou_1,0,1,21,0.81353,0.46885,2.41978,57,0.038739523809524,-3.25089491303743
1,Grenou_1,0,1,20.1,0.82752,0.46522,2.40977,57,0.041170149253731,-3.19004181790373
1,Grenou_1,0,1,26.8,0.98631,0.48447,2.68182,57,0.036802611940299,-3.30218645968743
1,Grenou_1,0,1,21.4,0.87054,0.45428,2.71523,57,0.040679439252337,-3.20203249225429
1,Grenou_1,0,1,18.9,0.83487,0.42868,2.7107,57,0.044173015873016,-3.11964117694036Le fichier est construit de la manière suivante
- 3 lignes de commentaires,
- une ligne qui indique le nom des colonnes, puis les données elles-mêmes
- le changement de colonnes est matérialisé par une virgule.
Nous allons donc expliquer ceci à R.
Etape 6 : Importation dans R
dta <- read.table(file = 'samares_small.csv', ## le nom du fichier qu'on souhaite lire
skip = 3, ## pour dire à R d'ignorer les 3 premières lignes de commentaires
header = TRUE, ## pour indiquer que les colonnes ont un nom
sep = ',' ## pour indiquer que le séparateur de colonnes est une virgule
) Normalement R n’indique aucune erreur.
On n’oublie pas de sauver régulièrement le script.
Etape 7. Vérifier l’importation
On doit voir apparaître dans l’onglet environnement un nouveau jeu de
données dta. Il est indiqué qu’il a 120 observations
(i.e. 120 lignes dans le jeu de données) et 11 variables (11 colonnes
dans le jeu de données).
On peut faire afficher les premières lignes pour vérifier qu’elles sont correctes
## Site NomSite Distance Arbre Poids Surface Largeur Longueur CircArbre
## 1 1 Grenou_1 0 1 16.8 0.83907 0.45758 2.46212 57
## 2 1 Grenou_1 0 1 25.4 0.80864 0.43251 2.47986 57
## 3 1 Grenou_1 0 1 21.7 0.77436 0.44081 2.35872 57
## 4 1 Grenou_1 0 1 14.9 0.86005 0.45292 2.63522 57
## 5 1 Grenou_1 0 1 21.0 0.81353 0.46885 2.41978 57
## 6 1 Grenou_1 0 1 20.1 0.82752 0.46522 2.40977 57
## dispersion log_disp
## 1 0.04994464 -2.996840
## 2 0.03183622 -3.447151
## 3 0.03568479 -3.333031
## 4 0.05772148 -2.852126
## 5 0.03873952 -3.250895
## 6 0.04117015 -3.190042ou les dernières
## Site NomSite Distance Arbre Poids Surface Largeur Longueur CircArbre
## 115 2 Grenou_2 0.2 3 29.4 0.80117 0.43407 2.59293 22
## 116 2 Grenou_2 0.2 3 21.9 0.72918 0.39925 2.43788 22
## 117 2 Grenou_2 0.2 3 29.5 1.02212 0.46271 2.99618 22
## 118 2 Grenou_2 0.2 3 29.0 0.68639 0.39900 2.39071 22
## 119 2 Grenou_2 0.2 3 27.8 0.77729 0.43905 2.57643 22
## 120 2 Grenou_2 0.2 3 27.5 0.83004 0.45817 2.62109 22
## dispersion log_disp
## 115 0.02725068 -3.602677
## 116 0.03329589 -3.402321
## 117 0.03464814 -3.362511
## 118 0.02366862 -3.743605
## 119 0.02796007 -3.576978
## 120 0.03018327 -3.500467On peut aussi demander un résumé du jeu de données qui va nous aider à vérifier que l’importation s’est bien déroulée.
## Site NomSite Distance Arbre Poids
## Min. :1.0 Length:120 Min. :0.0 Min. :1 Min. :13.80
## 1st Qu.:1.0 Class :character 1st Qu.:0.0 1st Qu.:1 1st Qu.:21.18
## Median :1.5 Mode :character Median :0.1 Median :2 Median :24.55
## Mean :1.5 Mean :0.1 Mean :2 Mean :25.44
## 3rd Qu.:2.0 3rd Qu.:0.2 3rd Qu.:3 3rd Qu.:29.00
## Max. :2.0 Max. :0.2 Max. :3 Max. :54.70
## Surface Largeur Longueur CircArbre
## Min. :0.6289 Min. :0.3613 Min. :1.782 Min. :22.00
## 1st Qu.:0.8071 1st Qu.:0.4259 1st Qu.:2.418 1st Qu.:28.00
## Median :0.8709 Median :0.4588 Median :2.596 Median :32.00
## Mean :0.9078 Mean :0.4809 Mean :2.575 Mean :39.75
## 3rd Qu.:0.9884 3rd Qu.:0.5379 3rd Qu.:2.711 3rd Qu.:57.00
## Max. :1.4495 Max. :0.7027 Max. :3.123 Max. :67.50
## dispersion log_disp
## Min. :0.02262 Min. :-3.789
## 1st Qu.:0.03016 1st Qu.:-3.501
## Median :0.03475 Median :-3.360
## Mean :0.03761 Mean :-3.317
## 3rd Qu.:0.04118 3rd Qu.:-3.190
## Max. :0.08671 Max. :-2.445Normalement Les variables quantitatives sont résumées quantitativement par le minimum, le premier quartile, la médiane, etc …. Tandis que les variables qualitatives sont interprétées comme des facteurs et sont résumées par le nombre d’occurences de chaque niveau du facteur.
Si toutes les vérifications sont correctes, votre jeu de données est prêt à être analysé.
Etape 8. Quand ça va mal
S’il n’y a pas de noms de colonnes dans le fichier
Il suffit d’indiquer header = FALSE, dans ce cas les
colonnes seront nommées V1, V2, etc
Les différents types de séparateurs
Si le séparateur de colonnes n’est pas la ,, alors il
faut modifier l’argument sep
| Séparateur dans le fichier | argument à passer |
|---|---|
| , | sep = ',' |
| ; | sep = ';' |
| espace | sep = ' ' |
| tab | sep = '\t' |
Problème possible avec les variables numériques
Il est possible avec une version française d’Excel, que le symbole
qui code pour la décimale ne soit pas le . qui est la
convention internationale mais le , qui est l’habitude
Française. Si on ne l’indique pas à R, il ne va pas comprendre que la
variable concernée est quantitative. Ceci sera visible dans le résumé de
la variable. Si tel est le cas, il suffit de rajouter l’argument
dec = ',' dans la fonction read.table (à
n’importe quel endroit ).
dta_wrong <- read.table(file = 'samares_small.csv', ## le nom du fichier qu'on souhaiote lire
skip = 3, ## pour dire à R d'ignorer les 3 premières lignes de commentaires
header = TRUE, ## pour indiquer que les colonnes ont un nom
sep = ',', ## pour indiquer que le séparateur de colonnes est une virgule
dec = ','
) Ici, puisque le signe de décimal était un point . mais
qu’on lui indique le contraire, on reprère justement un problème
lorsqu’on demande un résumé des données.
## Site NomSite Distance Arbre
## Min. :1.0 Length:120 Length:120 Min. :1
## 1st Qu.:1.0 Class :character Class :character 1st Qu.:1
## Median :1.5 Mode :character Mode :character Median :2
## Mean :1.5 Mean :2
## 3rd Qu.:2.0 3rd Qu.:3
## Max. :2.0 Max. :3
## Poids Surface Largeur Longueur
## Length:120 Length:120 Length:120 Length:120
## Class :character Class :character Class :character Class :character
## Mode :character Mode :character Mode :character Mode :character
##
##
##
## CircArbre dispersion log_disp
## Length:120 Length:120 Length:120
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
##
## Une colonne pour indiquer les noms des lignes
Si un identifiant est présent pour chaque ligne, on ajoute dans la
commande read.table l’argument row.names=1
pour indiquer que la première colonne sert à nommer les lignes.